🎧 音声概要 (※ NotebookLM で生成されており、誤りを含む場合があります)
以前、Readwise で日々ストックしている記事を DuckDB を用いてハイブリッド検索できるようにする、という記事を書きました。 キーワードが曖昧でも関連記事が見つかりやすくなり、とてもいい感じです。
次に欲しくなるのは、検索インターフェイスです。せっかくなので MCP server を作成して、MCP に対応しているクライアントから検索できるようにしてみます。
ちょうど、Raycast が v1.98.0 で MCP に対応したので、これを利用して Raycast から MCP 経由で記事を検索できるようにします。
MCP server の実装
早速 MCP server を実装していきましょう。 前回記事で作成した検索システムは Python で実装しているので、MCP server も Python で実装することにします。
公式の Python SDK があるのでこれを利用します。 詳しくは公式のチュートリアルも参照してください。
検索システムの MCP server 化は非常に簡単です。 まずは、MCP server の構築に必要な dependencies をインストールします。
uv add "mcp[cli]"
そして articles.py というファイルを作成し、前回記事のコードを移植しつつ、以下のようにMCP server に関するコードを追加します。
from mcp.server.fastmcp import FastMCP
# ...
# FastMCP server の初期化
mcp = FastMCP("arcticle-search")
# Tool execution handler の定義
# これが tools として呼び出せるようになる
@mcp.tool()
def query_data(query: str) -> str:
"""Query artickes from the database."""
try:
hybrid_search_result = hybrid_search_json(con, query, top_n=20)
return hybrid_search_result
except Exception as e:
return f"Error: {str(e)}"
if __name__ == "__main__":
# Server を実行する
mcp.run(transport="stdio")
最後に、以下のようにスクリプトを実行し、問題なく起動すれば Server の実装は完了です。
uv run articles.py
コード全体は下記を参照してください。
コード全体
例によって勢いで実装しているので、読みづらい点などあるかもしれません。ご容赦ください。
from mcp.server.fastmcp import FastMCP
import duckdb
import torch
import json
from lindera_py import Segmenter, Tokenizer, load_dictionary
from sentence_transformers import CrossEncoder
from transformers import AutoModel, AutoTokenizer
import pandas as pd
device = "cuda" if torch.cuda.is_available() else "cpu"
v_tokenizer = AutoTokenizer.from_pretrained(
"pfnet/plamo-embedding-1b", trust_remote_code=True
)
v_model = AutoModel.from_pretrained("pfnet/plamo-embedding-1b", trust_remote_code=True)
v_model = v_model.to(device)
dictionary = load_dictionary("ipadic")
segmenter = Segmenter("normal", dictionary)
tokenizer = Tokenizer(segmenter)
reranker = CrossEncoder(
"hotchpotch/japanese-bge-reranker-v2-m3-v1", device=device, max_length=512
)
con = duckdb.connect("article_search.duckdb")
con.install_extension("vss")
con.load_extension("vss")
con.install_extension("fts")
con.load_extension("fts")
mcp = FastMCP("arcticle-search")
def ja_tokens(text: str) -> str:
return " ".join(t.text for t in tokenizer.tokenize(text))
def fts_search(conn, query, k=5):
q = ja_tokens(query)
return conn.sql(f"""
SELECT id, title,
fts_main_articles.match_bm25(id, '{q}') AS score
FROM articles
WHERE score IS NOT NULL
ORDER BY score DESC
LIMIT {k}
""").fetchdf()
def vss_search(conn, query, k=5):
with torch.inference_mode():
q_emb = v_model.encode_query(query, v_tokenizer)
return conn.sql(
f"""
SELECT id, title,
array_cosine_distance(embedding, ?::FLOAT[2048]) AS dist
FROM articles
ORDER BY dist ASC
LIMIT {k}
""",
params=[q_emb.cpu().squeeze().numpy().tolist()],
).fetchdf()
def hybrid_search(conn, query, k_fts=10, k_vss=10, top_n=5):
fts_df = fts_search(conn, query, k_fts)
vss_df = vss_search(conn, query, k_vss)
pool = pd.concat([fts_df, vss_df]).drop_duplicates("id")
pairs = [(query, txt) for txt in pool["title"]]
scores = reranker.predict(pairs)
pool["score"] = scores
result_df = pool.sort_values("score", ascending=False).head(top_n)[
["id", "title", "score"]
]
return result_df
def hybrid_search_json(conn, query, k_fts=10, k_vss=10, top_n=5):
df = hybrid_search(conn, query, k_fts, k_vss, top_n)
# MEMO: 検証時に url を含めていなかったため id から url を作成する
df["url"] = df["id"].apply(lambda id: f"https://read.readwise.io/read/{id}")
results = df.to_dict(orient="records")
return json.dumps(results, ensure_ascii=False, indent=2)
@mcp.tool()
def query_data(query: str) -> str:
"""Query artickes from the database."""
try:
hybrid_search_result = hybrid_search_json(con, query, top_n=20)
return hybrid_search_result
except Exception as e:
return f"Error: {str(e)}"
if __name__ == "__main__":
print("Starting FastMCP server...")
mcp.run(transport="stdio")
Raycast に MCP server をインストール
MCP server の構築が完了したので、Raycast と繋ぎ込みます。
Raycast での MCP server のインストールは、"install server" と打ち込み、起動コマンドなどを打ち込むだけです。 詳しくは公式ドキュメントを参照してください。
以下のように設定項目を入力し、Install を実行します。
/path/to/project/dir はスクリプトがあるディレクトを絶対パスで指定してください

Fig. 1 Raycast で MCP server をインストールする
テスト
それでは実際に検索をしてみましょう。@search-articles コマンドを指定して、検索したいことを入力します。
例えば、「AIエージェントのプライシングの記事を検索して」と入力してみます。 すると、下図 Fig. 2 のように MCP Server の tools が実行され、検索結果が返ってきます。
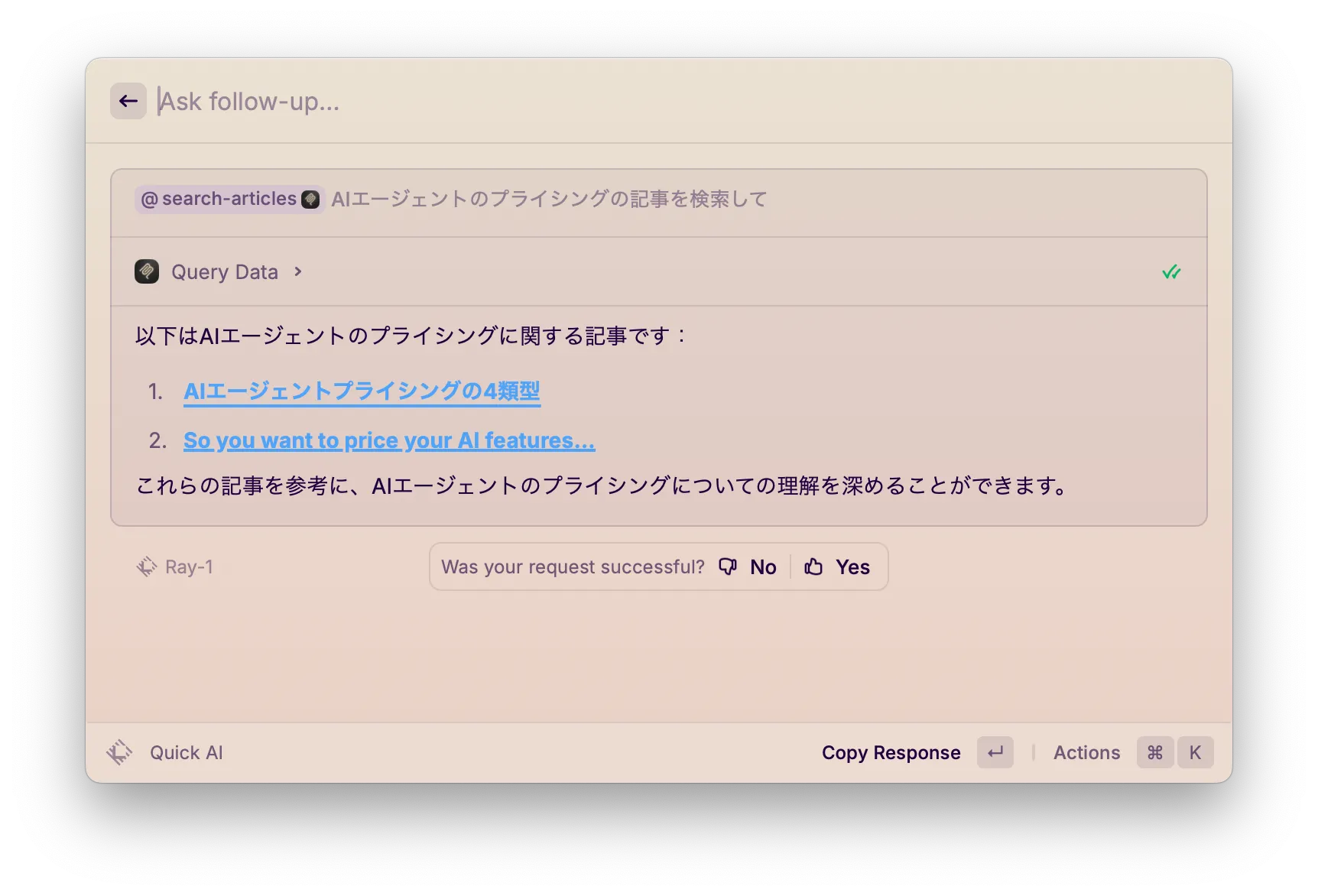
Fig. 2 実際にクエリを実行してみる
気軽にストックした記事を検索できて良い感じです!
ざっくりとした処理の流れは以下のとおりです。
- ユーザーが AI Chat に入力したプロンプトから、LLM が Tools に渡すクエリを考える
- そのクエリを引数に Tools (ここでは
query_data) を呼び出し、ハイブリッド検索を実行する - ハイブリッド検索の結果が返ってくる (上記コードでは上位 20 件)
- LLM が実行結果をコンテキストに含め、関連する記事をピックアップして出力を生成する
ハイブリッド検索の結果としては 20 件返すように設定していますが、Step 4 において LLM がさらに関連する記事を吟味するような構造になるため、検索するキーワードによっては出力に含まれる記事が数個になるパターンがあります。
Tools の実行を常に許可する
デフォルトでは、Tools を実行する際に許可を求められます。 Actions の設定から "Confirm Always" が指定できるので、これを用いて自動許可を設定することが可能です。
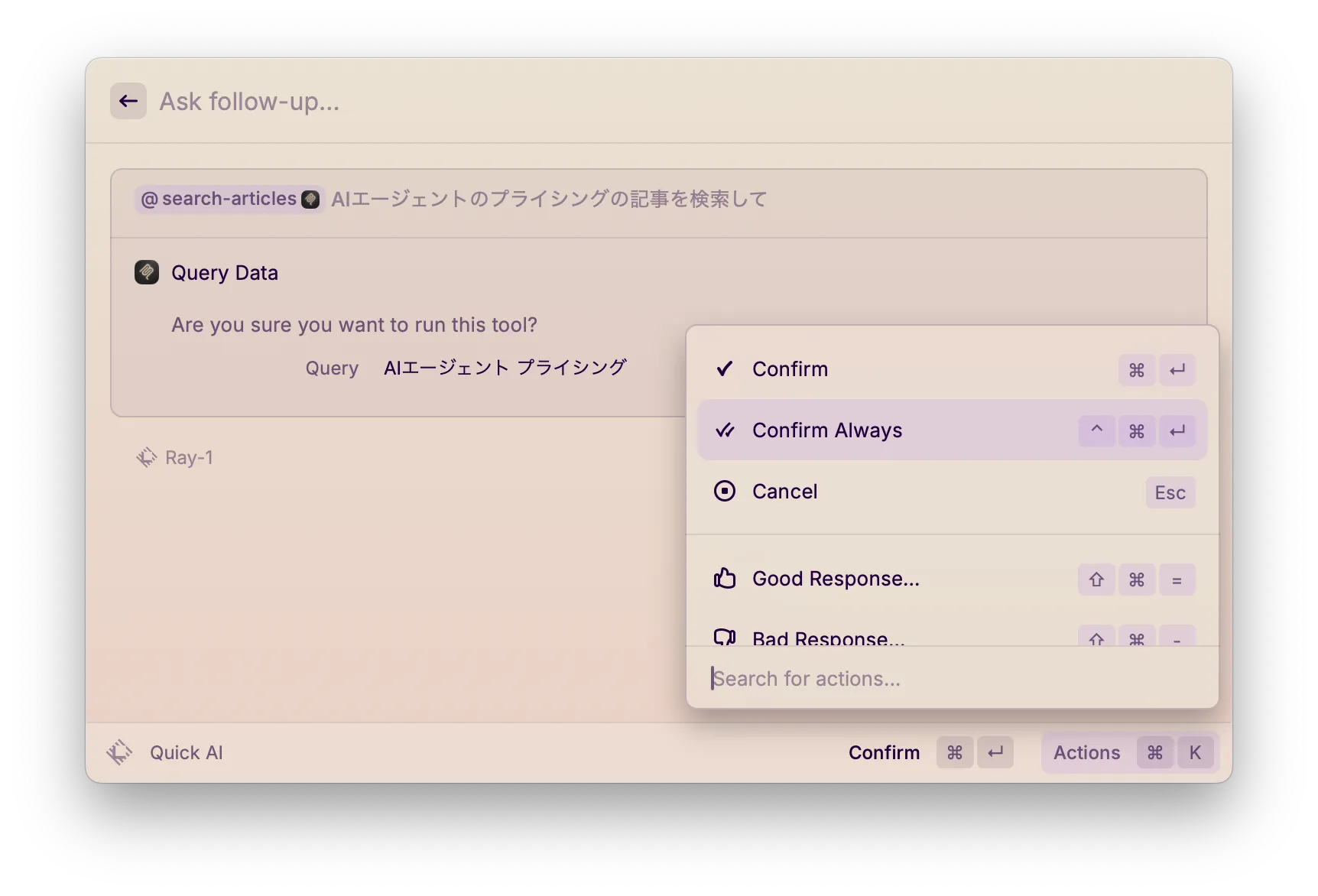
Fig. 3 "Confirm Always" を設定する
おわりに
Raycast をクライアントとして利用して、記事検索用に作成した MCP server と接続し、ストックした記事をハイブリッド検索する例を紹介しました。
Raycast という手慣れたツールを検索のインターフェイスにすることができるので、検索が捗ります。
また、今回は記事のタイトルのみを検索結果として返していますが、本文情報などを含めるなどすると、出力の情報量もより増えせると思います。ここは工夫のしがいがありますね。
最後までお読みいただきありがとうございました。